Архитектура kubernetes
Что же такое kubernetes? Обратимся к официальной страничке kubernetes в интернете:
Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications
На русский язык это переводится как "кубернетес - это система с открытым исходным кодом, разработанная для автоматизации развертывания, масштабирования и управления приложениями, работающими в изолированных контейнерах". Много красивых слов, и кубернетес действительно всё это делает, но для людей, котрые только начинают свой путь в мире изолированных контейнеров, они практически ничего не значат. Однако, если вы уже знакомы с docker и понимаете, зачем он нужен, то для вас достаточно знать, что kubernetes - это просто надстройка над docker, позволяющая объединять несколько узлов с установленным docker в кластер. Таким образом вы приобретаете отказоустойчивость раз, так как контейнеры, работающие на сбойном узле, будут перезапущены кубернетесом на другом, и балансировку нагрузки два, так как кубернетес старается нагружать свои узлы (ноды) равномерно.
Т.е. полноценный кубернетес кластер состоит из группы однотипно настроенных компьютеров - нод (виртуальных или реальных машин) и плюс еще один компьютер для самого кубренетеса. Конечно, никто не запрещает расположить все компоненты и на одном хосте, но смысл тогда теряется, так как, как мы уже говорили, основной задачей кубернетеса является обеспечение отказоустойчивости, а одна единственная машиа - это единая точка отказа.
На заметку. Кубернетес не ограничивается одним лишь докером и может работать поверх и других систем контейнерезации, таких как rkt или cri-o, но по-факту на сегодняшний день docker так и остается лидером в мире контейнеров, так что вы вряд ли встретите кубернетес, работающий на чем-то другом, кроме docker.
Однако такая особенность требует от вас установки на ноды специального компонента - kubelet (кубернетес-агента), который выступает слоем абстракции, т.е. в зависимости от того, что используется на бэкенде: docker, rkt или cri-o, kubelet будет дергать тот или иной движок, когда вы решите запустить какой-нибудь контейнер. Сам же kubernetes всегда использует один и тот же канал kubernetes <-> kubelet, что, безусловно, удобно.
Далее о чем стоит обязательно упомянуть, это база данных. Да-да, кубернетес нуждается в базе данных, и, в отличие от swarm, эта база данных не файловая. На текущий момент времени, единственной поддерживаемой базой данных для кубернетес является etcd. Это, на самом деле, очень даже не плохо, так как позволяет легко запускать несколько реплик кубернетеса, натравленных на одну и ту же базу данных, работающих вместе и обеспечивающих отказоустойчивость не только ваших приложений на нодах, но и самих себя, что очень важно в продакшне.
Давайте теперь обобщим все выше сказанное на схемах. Начнем с простого "одноголового" кластера kubernetes из 3-х нод
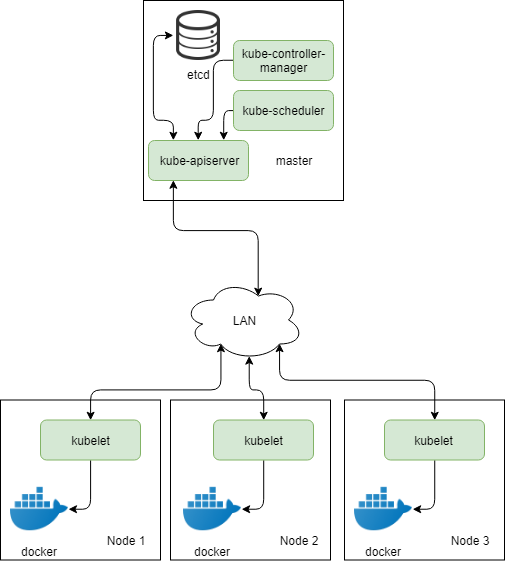
Как вы видите на схеме обозначены 3 ноды с установленным kubelet, настроенным на использование docker в качестве контейнерного движка, ядро кубернетеса и база данных etcd. Ядро состоит из API сервера, планировщика и контроллера. Все общение компонентов кубернетеса троится поверх протокола HTTP.
Kubernetes API сервер - это самый главный компонент, считайте это и есть kubernetes. Всё в kubernetes вертится вокруг API сервера - он является точкой входа для команд администратора, его адрес необходимо прописывать в конфигурационных файлах kubelet, чтобы тот смог зарегистрировать ноду в кластере kubernetes.
Завершают описание нашего кластера kubernetes два дополнительных компонента, носящих названия: kube-scheduler - программа, которая занимается вычислениями относительно того, на какой ноде лучше всего можно расположить тот или иной контейнер, и kube-controller-manager - программа, которая непрерывно следит за статусом как кластера самого, включая ноды, так и запущенных в нем контейнеров. Располагают эти компоненты как правило на тех же машинах, где уже работает kube-apiserver, ну хотя бы потому, что это немного расточительно выделять под эти нужды отдельные компьютеры, а сами машины-носители kube-apiserver, kube-scheduler и kube-controller-manager называют мастер-нодами, или просто мастер.
В отличие от тех, кто собирается запускать kubernetes на голом железе или в виртуальных машинах, пользователям разнообразных клаудов тут повезло сильнее, так как клауд-провайдер берет создание и обслуживание кубернетес мастера на себя, предоставляя вам за денежку уже готовый ендпоинт. Иногда клауд-провайдер, такой как, например, AWS, все-таки требует от вас создания и регистрации нод на мастере самостоятельно, но все равно это всё гораздо-гораздо легче, чем поднимать все компоненты самостоятельно, а потом настраивать их на работу друг с другом.
Но вернемся к рассмотрению архитектуру kubernetes. В схеме выше, как вы могли догадаться, присутствует один большой недостаток - да, она обеспечивает аптайм для вашего приложения, оперируя тремя нодами, но не обеспечивает безопасность самой себя. Мы уже упомянали о необходимости избегать единых точек отказа, и kubernetes поддерживает такую конфигурацию
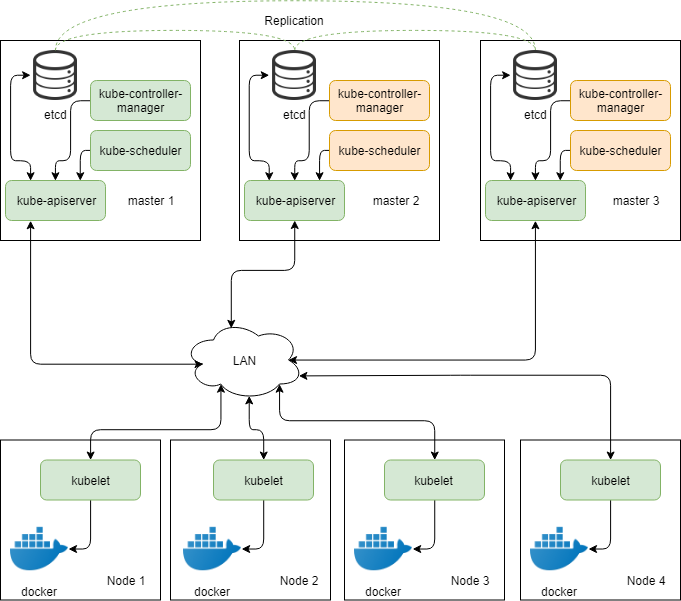
Как вы видите, мы не только увеличили число мастер-нод, но еще и увеличили количество инстансов etcd, чтобы исключить базу данных, как единую точку отказа. Такой шаг, само собой, требует настройки репликации на стороне etcd, чтобы выход одного узла из строя не только не сопровождался остановкой в работе, но и обеспечивал сохранность данных. В данном сценарии число интсансов (реплик) etcd необходимо поддерживать на уровне 3 и выше, чтобы избежать проблемы split brain, когда нода не может определить: толи это я потеряла связь с кластером, толи кластера больше нет. Никакая репликация на строне kube-apiserver не требуется, так как она уже обеспечивается etcd. А вот kube-scheduler и kube-controller-manager не могут сосуществовать одновременно, поэтому стартуя, они выбирают лидера, который будет делать всю работу, пока не упадет - тогда лидерство перейдет на другую ноду.
На заметку. Kubelet не может адресовать более одного API сервера в один и тот же момент времени, так что вам может потребоваться load balancer, такой, например, как keepalived, чтобы обеспечивать автоматическое переключение трафика на доступные API сервера в случае, если кто-то из них падает.
На этой стадии кластер считается уже полностью поднятым и функциональным. Однако есть еще несколько моментов, о которых мы не можем не поговорить, а именно межконтейнерное взаимодействие. Действительно, если ваши контейнеры нуждаются во взаимоействии друг с другом, то нужно каким-то образом обеспечить им такую возможность. По-умлочанию, docker стартует контейнеры, подключая их сетевые интерфейсы в обособленный бридж на хосте, что означает, что у контейнеров, запущенных на разных хостах, не будет возможности для обмена трафиком друг с другом. И решений у этой проблемы много. Трудность заключается в выборе того решения, которое подходит именно вам. Это может быть либо настоящий хардварный свитч, либо маршрут-трекер, либо VPN... Мы рассмотрим некоторые из таких решений в будущих статьях.
Темы
- Cloud (1)
- Coreutils (5)
- Data Bases (2)
- DNS (1)
- Docker (2)
- Kubernetes (4)
- Linux (34)
- Network (6)
- SystemD (8)
- VPN (1)
- WEB (2)
- Windows (4)
- Виртуализация (4)
![]()
Комментарии
Игорь (не проверено)
вс, 06/23/2019 - 23:01
Постоянная ссылка (Permalink)
Спасибо большое за такое
Sergey (не проверено)
вт, 08/20/2019 - 21:05
Постоянная ссылка (Permalink)
Node это и есть же worker
Михаил (не проверено)
пн, 08/19/2019 - 21:20
Постоянная ссылка (Permalink)
Спасибо за статью! Очень
Добавить комментарий